
A typical memory hierarchy of a multi-core processor.
![]() Cutting Edge Analytics
Cutting Edge Analytics
There is a large number of high performance processors available, each with its own characteristics, and the landscape is quickly changing with new processors being released. There are CPUs, GPUs, FPGAs, Xeon Phi, DSPs – to name just a few. How should one decide which of these processors to use for a particular task? Or should even a combination of these processors be used jointly to get the best performance? And then, how to manage the complexity of handling these devices? In the following, we’ll attempt to answer these questions.
The most common processor is the CPU. These are general purpose processors that can solve a wide range of computing problems. Today’s CPUs are multi-core (typically 2-22 cores), include several layers of cache, provide vector processing units, and include several instruction pipelines. This allows to run a number of tasks in parallel and optimise them for parallelism, cache utilisation, and vectorization. Each of the CPU cores is relatively big and complex, compared to the other processors described below. Further, various CPU architectures exist – such as x86, Power, or ARM – each with its own set of unique features and programming challenges.
The figure below illustrates the concepts of multi-core, cache hierarchies, and vector instructions for a typical CPU. Effective use of these features is essential for best performance.
A typical memory hierarchy of a multi-core processor.

Vector instructions process multiple data items in a single CPU instruction.
In recent years, graphics processing units (GPUs) became popular for general purpose computing. They include a large number of small processing cores (100-3000) in an architecture optimized for highly parallel workloads, typically paired with dedicated high performance memory. They are co-processors, used from a general purpose CPU, that can deliver very high performance for a subset of algorithms.

Nvidia Maxwell GPU architecture, with 2,048 CUDA cores (Source: Nvidia)
Intel Xeon Phi is a many-core accelerator processor based on the standard x86 CPU architecture, using many – but small – cores. It achieves its performance through high levels of parallelism, by parallel execution across cores, very wide vector units, and high memory bandwidth. It is a co-processor specifically designed for highly parallel workloads, paired with a general purpose CPU. Here is a benchmark which compares Xeon Phi to a GPU for a typical quantitative finance workload.
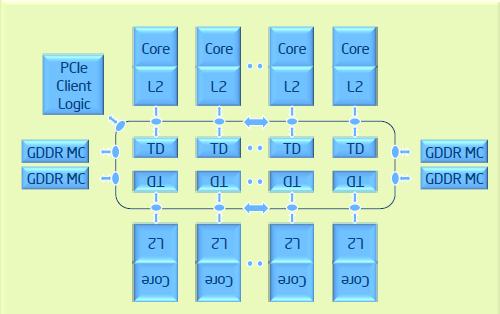
Xeon Phi Microarchitecture with 2 levels of cache and ring architecture (Source: Intel)
Traditionally, high performance tasks with real-time requirements have been managed by platforms such as field-programmable gate arrays (FPGAs) or digital signal processors (DSP). These devices are capable to achieve real-time performance for a subset of applications, consume low power, and offer high levels of parallelism. These devices are closer to integrated hardware and provide dedicated silicon for common tasks in the target application domain, most notably signal processing (e.g. multiply-add units, wide vector units, long pipelines, lookup-tables, on-chip memory, or shift registers). FPGAs and DSPs are specialised platforms aimed at specific application domains.
Each of these platforms has its own characteristics as shown in the table below:
| CPU | Phi | GPU | DSP | FPGA | |
| Raw Compute Power | medium | high | high | medium | high |
| Power Consumption | high | high | high | low | low |
| Latency | medium | high | high | low | low |
| Parallelism | medium | high | high | medium | high |
In most real-world applications, different parts of the application have different characteristics. Some parts can only run sequentially, some can be computed in parallel, others use large amounts of data – all within the same application. And worse yet, it is generally not known a priori just how well a particular application can work on a particular processor, as specific optimisations and restructuring might be required for each.
The following table summarizes how each discussed processor type is suited to a particular type of workload:
| Workload | CPU | Phi | GPU | DSP | FPGA |
| Sequential | high | low | low | low | low |
| Iterative | high | low | low | medium | medium |
| Data-Parallel | medium | high | high | high | high |
| Memory-intensive | high | medium | medium | low | low |
In computational finance, many compute-intensive algorithms are Monte-Carlo simulations. These are embarrassingly parallel by nature, but loading the data from files is inherently sequential. Further, especially in risk management, capital, and XVA calculations, large amounts of data need to be handled, which makes the application memory-intensive. American Monte-Carlo techniques for pricing callables and XVA, and PDE solvers for pricing and model calibration both include sequential / iterative components as well as parallel parts. With recent changes to regulations (e.g. FRTB SBA and SA-CVA and SIMM) and the need for better risk management, there is a pressing need to calculate sensitivities, dramatically increasing memory requirements and posing challenges to parallelisation.
Calculations in the energy exploration are memory-intensive, processing data up to the petabyte range. In both seismic imaging and reservoir modelling many large three-dimensional PDEs need to be solved, with both parallel and iterative parts. The calculations are performed on the world’s largest supercomputers, often including a hybrid combination of processors.
Other fields of scientific computing draw a similar picture. Most real-world applications do not fit into a single category mentioned in the table above. So clearly, one does not fit all – even within the same application, different platforms should be used for different parts of the application to achieve the best possible overall performance.
The traditional approach would be to maintain code bases for each specific hardware platform, each tuned for performance using techniques such as threading, vectorisation, cache optimisations, etc. Then the application can be tested on each platform to choose the best combination. With this, the code becomes platform-specific and separate maintenance for each platform is required. In a practical setup, algorithms and applications evolve with time and the hardware evolves as well. So if platform X performs slower than platform Y for the application A today, this might not hold in future. Multiple code-bases have to be maintained to be able to react to these changes – clearly not a practical solution.
Therefore, often compromises are taken: typically easy maintenance is favoured and performance is sacrificed. That is, the code is not optimised for a particular platform and developed for a standard CPU processor, as maintaining code bases for different accelerator processors is a difficult task and the benefit is not known beforehand or does not justify the effort.
It would be better if the source code could be written once, and existing tools and compilers would optimise automatically for the target hardware. This allows to exploit hybrid hardware configurations to the best advantage and is portable to future platforms.
So which hardware infrastructure should be chosen? It depends… the best performance can be achieved using a combination of different processors. The Future Is Hybrid! Each firm will have its own winning combination of processors, and each application will use a different combination. And this is subject to change – the software needs to be able to to follow the hardware evolution and at the same time deliver the performance.